Как редактировать файл robots txt. Как редактировать файл robots txt Для чего нужен файл robots txt
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса - информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено краулинговым бюджетом , который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt .
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта - , чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки если она медленная - и .
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt. Robots.txt - это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется "robots.txt ", название написано только строчными буквами, "Robots.TXT" и другие вариации не поддерживаются;
- располагается только в корневом каталоге - https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат.txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со ;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: "сайт.рф" - "xn--80aswg.xn--p1ai".
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами - http://web.site.com/robots.txt или нестандартными портами - http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
User-agent: * Disallow: /about/
Запись формата "Disallow: /about" без закрывающего "/" запретит доступ и к разделу
http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с "/about".
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот - директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с "/catalog", а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл "photo.html" разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам "site.com/catalog1/" и "site.com/catalog2/" но разрешить к "catalog2/subcatalog1/":
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
"www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123"
"www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123"
"www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123"
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
"www.example. com/some_dir/get_book.pl? book_id=123"
Для адресов вида:
"www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df"
"www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
"www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243"
"www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
"www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311"
"www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без "http://" и без закрывающего слэша "/".
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже не используют , если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay - время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания - 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке http://site.com/ sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Инструменты для составления и проверки robots.txt
Составить robots.txt бесплатно
поможет
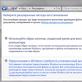
, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
 Графы инструмента для заполнения
Графы инструмента для заполнения
Для проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
Привет, начинающим вебмастерам!
После двух подготовительных уроков ( и ) можем переходить к практической части, а вернее к подготовке сайта к продвижению. Сегодня мы разберем вопрос: как создать robots.txt?
robots.txt – это файл в котором содержатся параметры индексирования для поисковых систем.
Создание этого файла является одним из первых шагов к SEO-продвижению. И вот почему.
Для чего нужен robots.txt?
После того, как вы добавите свой сайт в Яндекс и Google (мы пока это не проходили), ПС начнут индексировать все, абсолютно все, что находится в вашей папке с сайтом на сервере. Это не очень хорошо с точки зрения продвижения, ведь в папке содержится очень много не нужного для ПС “мусора”, что негативно скажется на позициях в поисковой выдаче.
Именно файл robots.txt запрещает индексирование документов, папок и ненужных страниц. Кроме всего прочего, здесь указывается путь к карте сайта (тема следующего урока) и главный адрес, об чуть подробнее.
О карте сайта я говорить много не буду, скажу лишь одно: карта сайта улучшает индексацию сайта. А вот про главный адрес стоит поговорить подробнее. Дело в том, что каждый сайт изначально имеет несколько зеркал (копий сайта) и доступны по различным адресам:
- www.сайт
- сайт
- сайт/
- www.сайт/
При наличии всех этих зеркал сайт становится не уникальным. Естественно, ПС не любят не уникальный контент, не давая таким сайтам подниматься в поисковой выдаче.
Как заполнить файл robots.txt?
Любой файл, предназначенный для работы с различными внешними сервисами, в нашем случае поисковыми системами, должен иметь правила заполнения (синтаксис). Вот правила для robots:
- Название файла robots.txt должно начинаться именно с маленькой буквы. Не нужно называть его ни Robots.txt, ни ROBOTS.TXT. Правильно: robots.txt ;
- Текстовый формат “Unix”. Формат свойственен обычному блокноту в Windows, поэтому создать robots.txt достаточно просто;
Операторы robots
А сейчас поговорим, собственно, о самих операторах robots. Всего их около 6 по-моему, но необходимыми являются только 4:
- User-agent . Данный оператор используется для указания поисковой системы, к которой адресуются правила индексации. С его помощью можно указывать разные правила разным ПС. Пример заполнения: User-agent: Yandex ;
- Disallow . Оператор, запрещающий индексацию той или папки, страницы, файла. Пример заполнения: Disallow: /page.html ;
- Host . Этим оператором указывается главный адрес (домен) сайта. Пример заполнения: Host: сайт ;
- Sitemap . Указывает на адрес карты сайта. Пример заполнения: Sitemap: сайт/sitemap.xml ;
Таким образом я запретил Яндексу индексировать страницу “page.. Теперь поисковый робот Яндекса учтет эти правила и страницы “page.html” никогда не будет в индексе.
User-agent
Как уже было сказано выше, в User-agent указывается поисковая система, к которой будут использованы правила индексации. Вот небольшая табличка:
| Поисковая система | Параметр User-agent |
| Яндекс | Yandex |
| Mail.ru | Mail.ru |
| Rambler | StackRambler |
Если вы хотите, чтобы правила индексации применялись для всех ПС, то нужно сделать такую запись:
User-agent: *
То есть, использовать, как параметр, обычную звездочку.
Disallow
С этим оператором чуть посложнее, поэтому нужно быть осторожным с его заполнением. Прописывается после оператора “User-agent”. Любая ошибка может привести к очень плачевным последствиям.
| Что запрещаем? | Параметр | Пример |
| Индексацию сайта | / | Disallow: / |
| Файл в корневом каталоге | /имя файла | Disallow: /page.html |
| Файл по определенному адресу | /путь/имя файла | Disallow: /dir/page.html |
| Индексация папки | /имя папки/ | Disallow: /papka/ |
| Индексация папки по определенному адресу | /путь/имя папки/ | Disallow: /dir/papka/ |
| Документы, начинающиеся с определенного набора символов | /символы | /symbols |
| Документы, начинающиеся с определенного набора символов по адресу | /путь/символы | /dir/symbols |
Еще раз говорю: будьте крайне внимательны при работе с данным оператором. Случается и такое, что чисто случайно человек запрещает индексацию своего сайта, а потом удивляется тому, что его нет в поиске.
Про остальные операторы говорить смысла нет. Того, что написано выше вполне достаточно.
Вам, наверное, хотелось бы получить пример robots.txt? Ловите:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Host: site.ru Sitemap:site.ru/sitemap.xml
Кстати, этот пример могут использовать, как настоящий файл robots.txt, люди, чьи сайты работают на WordPress. Ну а те, у кого обычные сайты, пишите сами, ха-ха-ха. К сожалению, одного единственного для всех не существует, у каждого он свой. Но с той информацией, которую я вам дал, создать robots.txt не составит большого труда.
До свидания, друзья!
Первое, что делает поисковый бот, который приходит на ваш сайт, это поиск и чтение файла robots.txt. Что это за файл? — это набор инструкций для поисковой системы.
Он представляет собой текстовый файл, с расширением txt, который находится в корневой директории сайта. Данный набор инструкций указывает поисковому роботу, какие страницы и файлы сайта индексировать, а какие нет. Так же в нем указывается основное зеркало сайта и где искать карту сайта.
Для чего нужен файл robots.txt? Для правильного индексирования вашего сайта. Что бы в поиске не было дублей страниц, различных служебных страниц и документов. Один раз правильно настроив директивы в robots вы убережете свой сайт от многих проблем с индексацией и зазеркаливанием сайта.
Как составить правильный robots.txt
Составить robots.txt достаточно легко, создаем текстовый документ в стандартном блокноте винды. Пишем в этом файле директивы для поисковых систем. Далее сохраняем этот файл под названием «robots» и текстовым расширением «txt». Все теперь его можно залить на хостинг, в корневую папку сайта. Учтите, для одного сайта можно создать только один документ «роботс». Если этот файл отсутствует на сайте, то бот автоматические «решает» что можно индексировать все.
Так как он один, то в нем прописываются инструкции ко всем поисковым системам. Причем можно записать как отдельно инструкции под каждую ПС, так и общую сразу под все. Разделение инструкций для различных поисковых ботов делается через директиву User-agent. Подробнее поговорим об этом ниже.
Директивы robots.txt
Файл «для роботов» может содержать следующие директивы для управления индексацией: User-agent, Disallow, Allow, Sitemap, Host, Crawl-delay, Clean-param. Давайте рассмотрим каждую инструкцию по подробней.
Директива User-agent
Директива User-agent — указывает для какой поисковой системы будут инструкции (точнее для какого конкретно бота). Если стоит «*» то инструкции предназначены для всех роботов. Если указан конкретный бот, например Googlebot, значит, инструкции предназначены только для основного индексирующего робота Google. Причем если инструкции есть и отдельно для Googlebot и для всех других ПС, то гугл прочтет только свою инструкцию, а общую проигнорирует. Бот Яндекса поступит так же. Смотрим пример записи директивы.
User-agent: YandexBot — инструкции только для основного индексирующего бота Яндекса
User-agent: Yandex — инструкции для всех бот Яндекса
User-agent: * — инструкции для всех ботов
Директивы Disallow и Allow
Директивы Disallow и Allow — дают команды что индексировать, а что нет. Disallow дает команду не индексировать страницу или целый раздел сайта. А Allow наоборот указывает, что нужно проиндексировать.
Disallow: / — запрещает индексировать весь сайт
Disallow: /papka/ — запрещает индексировать все содержимое папки
Disallow: /files.php — запрещает индексировать файл files.php
Allow: /cgi-bin – разрешает индексировать страницы cgi-bin
В директивах Disallow и Allow можно и зачастую просто необходимо использовать спецсимволы. Они нужны для задания регулярных выражений.
Спецсимвол * — заменяет любую последовательность символов. Он по умолчанию приписывается к концу каждого правила. Даже если вы его не прописали, ПС сами приставят. Пример использования:
Disallow: /cgi-bin/*.aspx – запрещает индексировать все файлы с расширением.aspx
Disallow: /*foto — запрещает индексацию файлов и папок содержащих слово foto
Спецсимвол $ — отменяет действие спецсимвола «*» в конце правила. Например:
Disallow: /example$ — запрещает индексировать ‘/example’, но не запрещает ‘/example.html’
А если прописать без спецсимвола $ то инструкция сработает уже по другому:
Disallow: /example — запрещает и ‘/example’ и ‘/example.html’
Директива Sitemap
Директива Sitemap — предназначена для указания роботу поисковой системы, в каком месте на хостинге лежит карта сайта. Формат карты сайта должен быть sitemaps.xml. Карта сайта нужна для более быстрой и полной индексации сайта. Причем карта сайта это не обязательно один файл, их может быть несколько. Формат записи директы:
Sitemap: http://сайт/sitemaps1.xml
Sitemap: http://сайт/sitemaps2.xml
Директива Host
Директива Host — указывает роботу основное зеркало сайта. Что бы не было в индексе зеркал сайта, всегда нужно указывать эту директиву. Если ее не указать, робот Яндекса будет индексировать как минимум две версии сайт с www и без. Пока робот зеркальщик их не склеит. Пример записи:
Host: www.сайт
Host: сайт
В первом случае робот будет индексировать версию с www, во втором случае без. Разрешается прописывать только одну директиву Host в файле robots.txt. Если вы пропишите их несколько, бот обработает и примет к сведению только первую.
Правильная директива хост должна иметь следующие данные:
— указывать на протокол соединения (HTTP или HTTPS);
— корректно написанное доменное имя (нельзя прописывать IP-адрес);
— номер порта при необходимости (например, Host: site.com:8080).
Не правильно сделанные директивы просто будут игнорированы.

Директива Crawl-delay
Директива Crawl-delay позволяет снизить нагрузку на сервер. Она нужна на случай если ваш сайт начинается ложиться под натиском различных ботов. Директива Crawl-delay указывает поисковому боту время ожидания между окончанием закачки одной страницы и началом закачки другой страницы сайта. Директива должна идти непосредственно после записей директив «Disallow» и/или «Allow». Поисковый робот Яндекса умеет читывать дробные значения. Например: 1.5 (полторы секунды).

Директива Clean-param
Директива Clean-param нужна сайтам, страницы которых содержат динамические параметры. Речь о тех, которые не влияют на содержимое страниц. Это различная служебная информация: идентификаторы сессий, пользователей, рефереров и т.д. Так вот, что бы не было дублей эти страниц и используется эта директива. Она скажет ПС не закачивать повторно добирающуюся информацию. Снизится и нагрузка на сервер и время обхода сайта роботом.
Clean-param: s /forum/showthread.php
Данная запись говорит ПС, что параметр s будет считаться незначительным для для всех url, которые начинаются с /forum/showthread.php. Максимальная длина записи 500 символов.
С директивами разобрались, переходим к настройке нашего файла роботс.
Настройка robots.txt
Приступаем непосредственно к настройке файла robots.txt. Он должен содержать как минимум две записи:
User-agent:
— указывает для какой поисковой системы будут идущие ниже инструкции.
Disallow:
— уточняет, какую именно часть сайта не индексировать. Может закрывать от индексации, как отдельную страницу сайта, так и целые разделы.
Причем можно указать, что эти директивы предназначены для всех поисковых систем, или для какой-то одной конкретно. Указывается это в директиве User-agent. Если вы хотите что бы инструкции читали все боты — ставим «звездочку»
Если хотите прописать инструкции для конкретного робота, но надо указать его имя.
User-agent: YandexBot
Упрощенно пример правильно составленного файла robots будет таким:
User-agent: *
Disallow: /files.php
Disallow: /razdel/
Host: сайт
Где, *
говорит о том, что инструкции предназначены для всех ПС;
Disallow: /files.php
– дает запрет на индексацию файла file.php;
Disallow: /foto/
— запрещает индексировать целиком весь раздел «foto» со всеми вложенными файлами;
Host: сайт
— указывает роботам, какое зеркало индексировать.
Если у вас на сайте нет страниц, которые надо закрыть от индексации, то ваш файл robots.txt должен быть таким:
User-agent: *
Disallow:
Host: сайт
Robots.txt для Яндекса (Yandex)
Что бы указать, что данные инструкции предназначены для поисковой системы Яндекс, надо прописать в директиве User-agent: Yandex. Причем если мы пропишем «Yandex» то сайт будут индексировать все роботы Яндекса, а если укажем «YandexBot» — то это будет команда только для основного индексирующего робота.
Так же надо обязательно прописать директиву «Host», где указать основное зеркало сайта. Как я писал выше, делается это для недопущения дублей страниц. Ваш правильный robots.txt для Yandex будет таким.
Всем привет! Сегодня я бы хотел Вам рассказать про файл robots.txt . Да, про него очень много чего написано в интернете, но, если честно, я сам очень долгое время не мог понять, как же создать правильный robots.txt. В итоге я сделал один и он стоит на всех моих блогах. Проблем с я не замечаю, robots.txt работает просто великолепно.
Robots.txt для WordPress
А зачем, собственно говоря, нужен robots.txt? Ответ все тот же – . То есть составление robots.txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress. Поэтому не забудьте подписаться на RSS , чтобы не пропустить интересные материалы.).
Одна из функций данного файла – запрет индексации ненужных страниц сайта. Также в нем задается адрес и прописывается главное зеркало сайта (сайт с www или без www).
Примечание: для поисковых систем один и тот же сайт с www и без www совсем абсолютно разные сайты. Но, поняв, что содержимое этих сайтов одинаковое, поисковики “склеивают” их. Поэтому важно прописать главное зеркало сайта в robots.txt. Чтобы узнать, какое главное (с www или без www), просто наберите адрес своего сайта в браузере, к примеру, с www, если Вас автоматически перебросит на тот же сайт без www, значит главное зеркало Вашего сайта без www. Надеюсь правильно объяснил.
Так вот, этот заветный, по-моему, правильный robots.txt для WordPress Вы можете увидеть ниже.
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: сайт
.gz
Sitemap: https://сайт/sitemap.xml
Все что дано выше, Вам нужно скопировать в текстовой документ с расширением.txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы . Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Те, кому же лень создавать данный текстовой файл, можете просто скачать robots.txt и также там подкорректировать 3 строчки.
Хочу отметить, что в техническими частями, о которых речь пойдет ниже, себя сильно загружать не нужно. Привожу их для “знаний”, так сказать общего кругозора, чтобы знали, что и зачем нужно.
Итак, строка:
User-agent
задает правила для какого-то поисковика: к примеру “*” (звездочкой) отмечено, что правила для всех поисковиков, а то, что ниже
User-agent: Yandex
означает, что данные правила только для Яндекса.
Disallow
Здесь же Вы “засовываете” разделы, которые НЕ нужно индексировать поисковикам. К примеру, на странице https://сайт/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
Disallow: /tag
Так вот, в том robots.txt, который дан выше, от индексации закрыты почти все ненужные разделы сайта на WordPress, то есть просто оставьте все как есть.
Host
Здесь мы задаем главное зеркало сайта, о котором я рассказывал чуть выше.
Sitemap
В последних двух строчках мы задаем адрес до двух карт сайта, созданные с помощью .
Возможные проблемы
А вот из-за этой строчки в robots.txt, у меня перестали индексироваться посты сайта:
Disallow: /*?*
Как видите, эта самая строка в robots.txt запрещает индексирование статей, что естественно нам нисколько не нужно. Чтобы исправить это, просто нужно удалить эти 2 строчки (в правилах для всех поисковиков и для Яндекса) и окончательный правильный robots.txt для WordPress сайта без ЧПУ будет выглядеть следующим образом:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: сайт
Sitemap: https://сайт/sitemap.xml
Чтобы проверить, правильно ли мы составили файл robots.txt я рекомендую Вам воспользоваться сервисом Яндекс Вебмастер (как регистрироваться в данном сервисе я рассказывал ).
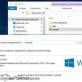
Заходим в раздел Настройки индексирования –> Анализ robots.txt:
Уже там нажимаете на кнопку “Загрузить robots.txt с сайта”, а затем нажимаете на кнопку “Проверить”:
Если Вы увидите примерно следующее сообщение, значит у Вас правильный robots.txt для Яндекса:

Приветствую вас, уважаемые читатели SEO блога Pingo. В данной статье я хочу изложить своё представление о том, как правильно составить robots.txt для сайта. В своё время меня очень раздражало, что информация в интернете по этому вопросу довольно отрывочна. Из-за этого приходилось ползать по большому количеству ресурсов, постоянно фильтруя повторяющуюся информацию и вычленяя новую.
Таким образом, здесь я постараюсь ответить на большинство вопросов, начиная с определения и заканчивая примерами реальных задач, решаемых данным инструментом. Если что-то забуду - отпишитесь в комментариях об этом - исследую вопрос и дополню материал.
Robots.txt - что это, зачем нужен и где обитает?
Итак, сперва ликбез для тех, кому данная тема незнакома совершенно.
Robots.txt - текстовый файл, содержащий инструкции по индексации сайта для роботов поисковых систем. В этом файле вебмастер может определить параметры индексации своего сайта как для всех роботов сразу, так и для каждой поисковой системы по отдельности (например, для гугла).
Где находится robots.txt? Он размещается в корневой папке FTP сайта, и, по сути, является обычным документом в формате txt, редактирование которого можно осуществлять через любой текстовый редактор (лично я предпочитаю Notepad++). Содержимое файла роботс можно увидеть, введя в адресной строке браузера http://www.ваш-сайт.ru/robots.txt. Если, конечно, он существует.
Как создать robots.txt для сайта? Достаточно сделать обычный текстовый файл с таким именем и загрузить его на сайт. О том, как его правильно настроить и составить, будет сказано ниже.
Структура и правильная настройка файла robots.txt
Как должен выглядеть правильный файл robots txt для сайта? Структуру можно описать следующим образом:
1. Директива User-agent
Что писать в данном разделе? Эта директива определяет то, для какого именно робота предназначены нижеизложенные инструкции. Например, если они предназначены для всех роботов, то достаточно следующей конструкции:
В синтаксисе файла robots.txt знак «*» равноценен словосочетанию «что угодно». Если же требуется задать инструкции для конкретной поисковой системы или робота, то на месте звездочки из предыдущего примера пишется его название, например:
User-agent: YandexBot
У каждого поисковика существует целый набор роботов, выполняющих те или иные функции. Роботы поисковой системы Яндекс описаны . В общем же плане имеется следующее:
- Yandex - указание на роботов Яндекс.
- GoogleBot - основной индексирующий робот .
- MSNBot - основной индексирующий робот Bing.
- Aport - роботы Aport.
- Mail.Ru - роботы ПС Mail.
Если имеется директива для конкретной поисковой системы или робота, то общие игнорируются.
2. Директива Allow
Разрешает отдельные страницы раздела, если, скажем, ранее он целиком закрыт от индексации. Например:
User-agent: *
Disallow: /
Allow: /открытая-страница.html
В данном примере мы запрещаем к индексации весь сайт, кроме страницы poni.html
Служит эта директива в какой-то степени для указания на исключения из правил, заданных директивой Disallow. В случае, если таких ситуаций нет, то директива может не использоваться совсем. Она не позволяет открыть сайт для индексации, как многие думают, так как если нет запрета вида Disallow: /, то он открыт по умолчанию.
2. Директива Disallow
Является антиподом директивы Allow и закрывает от индексации отдельные страницы, разделы или сайт целиком. Являет аналогом тега noindex. Например:
User-agent: *
Disallow: /закрытая-страница.html
3. Директива Host
Используется только для Яндекса и указывает на основное зеркало сайта. Выглядит это так.
Основное зеркало без www:
Основное зеркало с www:
Host: www.site.ru
Сайт на https:
Host: https://site.ru
Нельзя записывать директиву host в файл дважды. Если же вследствие какой-то ошибки это произошло, то обрабатывается та директива, которая идет первой, а вторая - игнорируется.
4. Директива Sitemap
Используется для указания пути к XML-карте сайта sitemap.xml (если она есть). Синтаксис следующий:
Sitemap: http://www.site.ru/sitemap.xml
5. Директива Clean-param
Используется для закрытия от индексации страниц с параметрами, которые могут являться дублями. Очень полезная на мой взгляд директива, которая отсекает параметрический хвост урлов, оставляя только костяк, который и является родоначальным адресом страницы.
Особенно часто встречается такая проблема при работе с каталогами и интернет-магазинами.
Скажем, у нас имеется страница:
http://www.site.ru/index.php
И эта страница в процессе работы может обрастать клонами вида.
http://www.site.ru/index.php?option=com_user_view=remind
http://www.site.ru/index.php?option=com_user_view=reset
http://www.site.ru/index.php?option=com_user_view=login
Для того, чтобы избавиться от всевозможных вариантов этого спама, достаточно указать следующую конструкцию:
Clean-param: option /index.php
Синтаксис из примера, думаю, понятен:
Clean-param: # указываем директиву
option # указываем спамный параметр
/index.php # указываем костяк урла со спамным параметром
Если параметров несколько, то просто перечисляем их через амперсант(&):
http://www.site.ru/index.php?option=com_user_view=remind&size=big # урл с двумя параметрами
Clean-param: option&big /index.php # указаны два параметра через амперсант
Пример взят простой, поясняющий саму суть. Особенно спасибо этому параметру хочется сказать при работе с CMS Bitrix.
Директива Crawl-Delay
Позволяет задать таймаут на загрузку страниц сайта роботом Яндекс. Используется при большой загруженности сервера, при которой он просто не успевает быстро отдавать содержимое. На мой взгляд, это анахронизм, который уже не учитывается и который можно не использовать.
Crawl-delay: 3.5 #таймаут в 3,5 секунды
Синтаксис
- # - используется для написания комментариев:
- * - означает любую последовательность символов, значение:
- $ - обрезание правила, антипод знака звездочки:
User-agent: * # директива относится ко всем роботам
Disallow: /page* # запрет всех страниц, начинающихся на page
Disallow: /*page # запрет всех страниц, заканчивающихся на page
Disallow: /cgi-bin/*.aspx # запрет всех aspx страниц в папке cgi-bin
Disallow: /page$ # будет закрыта только страница /page, а не /page.html или pageline.html
Пример файла robots.txt
С целью закрепления понимания вышеописанной структуры и правил, приведем стандартный robots txt для CMS Data Life Engine.
User-agent: * # директивы предназначены для всех поисковых систем
Disallow: /engine/go.php # запрещаем отдельные разделы и страницы
Disallow: /engine/download.php #
Disallow: /user/ #
Disallow: /newposts/ #
Disallow: /*subaction=userinfo # закрываем страницы с отдельными параметрами
Disallow: /*subaction=newposts #
Disallow: /*do=lastcomments #
Disallow: /*do=feedback #
Disallow: /*do=register #
Disallow: /*do=lostpassword #
Host: www.сайт # указываем главное зеркало сайта
Sitemap: https://сайт/sitemap.xml # указываем путь до карты сайта
User-agent: Aport # указываем направленность правил на ПС Aport
Disallow: / # предположим, не хотим мы с ними дружить
Проверка robots.txt
Как проверить robots txt на корректность составления? Стандартный вариант - валидатор Яндекса - http://webmaster.yandex.ru/robots.xml . Вводим путь до вашего файла роботс или сразу вставляем его содержимое в текстовое поле. Вводим список урлов, которые мы хотим проверить - закрыты или открыты они согласно заданным директивам - нажимаем «Проверить» и вуаля! Профит.
Выводится статус страницы - открыта ли она для индексации или закрыта. Если закрыта, то указывается, каким именно правилом. Чтобы разрешить индексацию такой страницы, нужно доработать правило, на которое указывает валидатор. Если в файле имеются синтаксические ошибки, то валидатор также об этом сообщит.
Генератор robots.txt - создание в режиме онлайн
Если изучать синтаксис желания или времени нет, но необходимость закрыть спамные страницы сайта присутствует, то можно воспользоваться любым бесплатным онлайн генератором , который позволит создать robots txt для сайта всего парой кликов. Затем вам останется лишь скачать файл и загрузить его к себе на сайт. При работе с ним вам лишь необходимо проставить галочки у очевидных настроек, а также указать страницы, которые вы хотите закрыть от индексации. Остальное генератор сделает за вас.

Готовые файлы для популярных CMS
Файл robots.txt для сайта на 1C Битрикс
User-Agent: *
Disallow: /bitrix/
Disallow: /personal/
Disallow: /upload/
Disallow: /*login*
Disallow: /*auth*
Disallow: /*search
Disallow: /*?sort=
Disallow: /*gclid=
Disallow: /*register=
Disallow: /*?per_count=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*logout=
Disallow: /*back_url_admin=
Disallow: /*print=
Disallow: /*backurl=
Disallow: /*BACKURL=
Disallow: /*back_url=
Disallow: /*BACK_URL=
Disallow: /*ADD2BASKET
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*DELETE_FROM_COMPARE_LIST
Disallow: /*action=BUY
Disallow: /*set_filter=y
Disallow: /*?mode=matrix
Disallow: /*?mode=listitems
Disallow: /*openstat
Disallow: /*from=adwords
Disallow: /*utm_source
Host: www.site.ru
Robots.txt для DataLife Engine (DLE)
User-agent: *
Disallow: /engine/go.php
Disallow: /engine/download.php
Disallow: /engine/classes/highslide/
Disallow: /user/
Disallow: /tags/
Disallow: /newposts/
Disallow: /statistics.html
Disallow: /*subaction=userinfo
Disallow: /*subaction=newposts
Disallow: /*do=lastcomments
Disallow: /*do=feedback
Disallow: /*do=register
Disallow: /*do=lostpassword
Disallow: /*do=addnews
Disallow: /*do=stats
Disallow: /*do=pm
Disallow: /*do=search
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Disallow: *print
Disallow: /*utm_source
Disallow: /*mailto*
Disallow: /*start*
Disallow: /*feed*
Disallow: /*search*
Disallow: /*users*
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt для Wordpress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: */trackback
Disallow: */feed
Disallow: /wp-login.php
Disallow: /wp-register.php
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt для Ucoz
User-agent: *
Disallow: /a/
Disallow: /stat/
Disallow: /index/1
Disallow: /index/2
Disallow: /index/3
Disallow: /index/5
Disallow: /index/7
Disallow: /index/8
Disallow: /index/9
Disallow: /panel/
Disallow: /admin/
Disallow: /secure/
Disallow: /informer/
Disallow: /mchat
Disallow: /search
Disallow: /shop/order/
Disallow: /?ssid=
Disallow: /google
Disallow: /