Как создать собственную нейронную сеть с нуля на языке Python. Основы Python
Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, . Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры .
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Что такое нейронная сеть?
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
Нейронные сети состоят из следующих компонентов:
- входной слой, x
- произвольное количество скрытых слоев
- выходной слой, ŷ
- набор весов и смещений между каждым слоем W и b
- выбор для каждого скрытого слоя σ ; в этой работе мы будем использовать функцию активации Sigmoid
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Обучение нейронной сети
Выход ŷ простой двухслойной нейронной сети:
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как .
Каждая итерация обучающего процесса состоит из следующих шагов
- вычисление прогнозируемого выхода ŷ, называемого прямым распространением
- обновление весов и смещений, называемых
Последовательный график ниже иллюстрирует процесс:

Прямое распространение
Как мы видели на графике выше, прямое распространение - это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Функция потери
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок - это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения - найти набор весов и смещений, который минимизирует функцию потери.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции - это тангенс угла наклона функции.

Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется .
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.
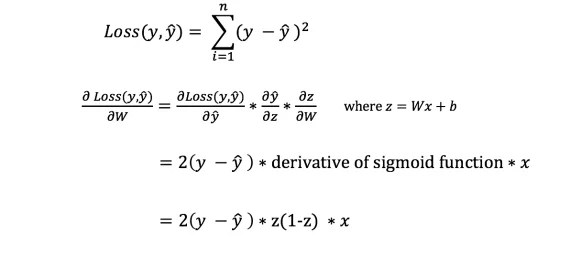
Фух! Это было громоздко, но позволило получить то, что нам нужно - производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Проверка работы нейросети
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весов Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.
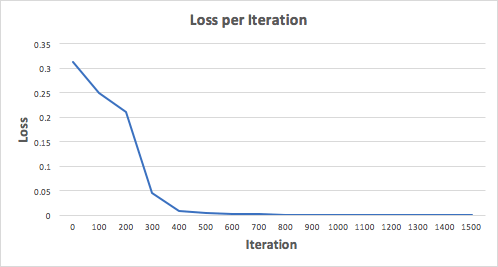
Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.

Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Финальные размышления
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!
- Перевод
О чём статья
Лично я лучше всего обучаюсь при помощи небольшого работающего кода, с которым могу поиграться. В этом пособии мы научимся алгоритму обратного распространения ошибок на примере небольшой нейронной сети, реализованной на Python.Дайте код!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 for j in xrange(60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0)))) l2 = 1/(1+np.exp(-(np.dot(l1,syn1)))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1)) syn1 += l1.T.dot(l2_delta) syn0 += X.T.dot(l1_delta)Слишком сжато? Давайте разобьём его на более простые части.
Часть 1: Небольшая игрушечная нейросеть
Нейросеть, тренируемая через обратное распространение (backpropagation), пытается использовать входные данные для предсказания выходных.Предположим, нам нужно предсказать, как будет выглядеть колонка «выход» на основе входных данных. Эту задачу можно было бы решить, подсчитав статистическое соответствие между ними. И мы бы увидели, что с выходными данными на 100% коррелирует левый столбец.
Обратное распространение, в самом простом случае, рассчитывает подобную статистику для создания модели. Давайте попробуем.
Нейросеть в два слоя
import numpy as np # Сигмоида def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x)) # набор входных данных X = np.array([ , , , ]) # выходные данные y = np.array([]).T # сделаем случайные числа более определёнными np.random.seed(1) # инициализируем веса случайным образом со средним 0 syn0 = 2*np.random.random((3,1)) - 1 for iter in xrange(10000): # прямое распространение l0 = X l1 = nonlin(np.dot(l0,syn0)) # насколько мы ошиблись? l1_error = y - l1 # перемножим это с наклоном сигмоиды # на основе значений в l1 l1_delta = l1_error * nonlin(l1,True) # !!! # обновим веса syn0 += np.dot(l0.T,l1_delta) # !!! print "Выходные данные после тренировки:" print l1Выходные данные после тренировки: [[ 0.00966449] [ 0.00786506] [ 0.99358898] [ 0.99211957]]
Переменные и их описания.
"*" - поэлементное умножение – два вектора одного размера умножают соответствующие значения, и на выходе получается вектор такого же размера
"-" – поэлементное вычитание векторов
x.dot(y) – если x и y – это вектора, то на выходе получится скалярное произведение. Если это матрицы, то получится перемножение матриц. Если матрица только одна из них – это перемножение вектора и матрицы.
- сравните l1 после первой итерации и после последней
- посмотрите на функцию nonlin.
- посмотрите, как меняется l1_error
- разберите строку 36 – основные секретные ингредиенты собраны тут (отмечена!!!)
- разберите строку 39 – вся сеть готовится именно к этой операции (отмечена!!!)
Разберём код по строчкам
import numpy as npИмпортирует numpy, библиотеку линейной алгебры. Единственная наша зависимость.
Def nonlin(x,deriv=False):
Наша нелинейность. Конкретно эта функция создаёт «сигмоиду». Она ставит в соответствие любое число значению от 0 до 1 и преобразовывает числа в вероятности, а также имеет несколько других полезных для тренировки нейросетей свойств.
If(deriv==True):
Эта функция также умеет выдавать производную сигмоиды (deriv=True). Это одно из её полезных свойств. Если выход функции – это переменная out, тогда производная будет out * (1-out). Эффективно.
X = np.array([ , …
Инициализация массива входных данных в виде numpy-матрицы. Каждая строка – тренировочный пример. Столбцы – это входные узлы. У нас получается 3 входных узла в сети и 4 тренировочных примера.
Y = np.array([]).T
Инициализирует выходные данные. ".T" – функция переноса. После переноса у матрицы y есть 4 строки с одним столбцом. Как и в случае входных данных, каждая строка – это тренировочный пример, и каждый столбец (в нашем случае один) – выходной узел. У сети, получается, 3 входа и 1 выход.
Np.random.seed(1)
Благодаря этому случайное распределение будет каждый раз одним и тем же. Это позволит нам проще отслеживать работу сети после внесения изменений в код.
Syn0 = 2*np.random.random((3,1)) – 1
Матрица весов сети. syn0 означает «synapse zero». Так как у нас всего два слоя, вход и выход, нам нужна одна матрица весов, которая их свяжет. Её размерность (3, 1), поскольку у нас есть 3 входа и 1 выход. Иными словами, l0 имеет размер 3, а l1 – 1. Поскольку мы связываем все узлы в l0 со всеми узлами l1, нам требуется матрица размерности (3, 1).
Заметьте, что она инициализируется случайным образом, и среднее значение равно нулю. За этим стоит достаточно сложная теория. Пока просто примем это как рекомендацию. Также заметим, что наша нейросеть – это и есть эта самая матрица. У нас есть «слои» l0 и l1, но они представляют собой временные значения, основанные на наборе данных. Мы их не храним. Всё обучение хранится в syn0.
For iter in xrange(10000):
Тут начинается основной код тренировки сети. Цикл с кодом повторяется многократно и оптимизирует сеть для набора данных.
Первый слой, l0, это просто данные. В X содержится 4 тренировочных примера. Мы обработаем их все и сразу – это называется групповой тренировкой . Итого мы имеем 4 разных строки l0, но их можно представить себе как один тренировочный пример – на этом этапе это не имеет значения (можно было загрузить их 1000 или 10000 без всяких изменений в коде).
L1 = nonlin(np.dot(l0,syn0))
Это шаг предсказания. Мы позволяем сети попробовать предсказать вывод на основе ввода. Затем мы посмотрим, как это у неё получается, чтобы можно было подправить её в сторону улучшения.
В строке содержится два шага. Первый делает матричное перемножение l0 и syn0. Второй передаёт вывод через сигмоиду. Размерности у них следующие:
(4 x 3) dot (3 x 1) = (4 x 1)
Матричные умножения требуют, чтобы в середине уравнения размерности совпадали. Итоговая матрица имеет количество строк, как у первой, а столбцов – как у второй.
Мы загрузили 4 тренировочных примера, и получили 4 догадки (матрица 4х1). Каждый вывод соответствует догадке сети для данного ввода.
L1_error = y - l1
Поскольку в l1 содержатся догадки, мы можем сравнить их разницу с реальностью, вычитая её l1 из правильного ответа y. l1_error – вектор из положительных и отрицательных чисел, характеризующий «промах» сети.
А вот и секретный ингредиент. Эту строку нужно разбирать по частям.
Первая часть: производная
Nonlin(l1,True)
L1 представляет три этих точки, а код выдаёт наклон линий, показанных ниже. Заметьте, что при больших значениях вроде x=2.0 (зелёная точка) и очень малые, вроде x=-1.0 (фиолетовая) линии имеют небольшой уклон. Самый большой угол у точки х=0 (голубая). Это имеет большое значение. Также отметьте, что все производные лежат в пределах от 0 до 1.

Полное выражение: производная, взвешенная по ошибкам
L1_delta = l1_error * nonlin(l1,True)
Математически существуют более точные способы, но в нашем случае подходит и этот. l1_error – это матрица (4,1). nonlin(l1,True) возвращает матрицу (4,1). Здесь мы поэлементно их перемножаем, и на выходе тоже получаем матрицу (4,1), l1_delta.
Умножая производные на ошибки, мы уменьшаем ошибки предсказаний, сделанных с высокой уверенностью. Если наклон линии был небольшим, то в сети содержится либо очень большое, либо очень малое значение. Если догадка в сети близка к нулю (х=0, у=0,5), то она не особенно уверенная. Мы обновляем эти неуверенные предсказания и оставляем в покое предсказания с высокой уверенностью, умножая их на величины, близкие к нулю.
Syn0 += np.dot(l0.T,l1_delta)
Мы готовы к обновлению сети. Рассмотрим один тренировочный пример. В нём мы будем обновлять веса. Обновим крайний левый вес (9.5)

Weight_update = input_value * l1_delta
Для крайнего левого веса это будет 1.0 * l1_delta. Предположительно, это лишь незначительно увеличит 9.5. Почему? Поскольку предсказание было уже достаточно уверенным, и предсказания были практически правильными. Небольшая ошибка и небольшой наклон линии означает очень небольшое обновление.

Но поскольку мы делаем групповую тренировку, указанный выше шаг мы повторяем для всех четырёх тренировочных примеров. Так что это выглядит очень похоже на изображение вверху. Так что же делает наша строчка? Она подсчитывает обновления весов для каждого веса, для каждого тренировочного примера, суммирует их и обновляет все веса – и всё одной строкой.
Понаблюдав за обновлением сети, вернёмся к нашим тренировочным данным. Когда и вход, и выход равны 1, мы увеличиваем вес между ними. Когда вход 1, а выход – 0, мы уменьшаем вес.
Вход Выход 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
Таким образом, в наших четырёх тренировочных примерах ниже, вес первого входа по отношению к выходу будет постоянно увеличиваться или оставаться постоянным, а два других веса будут увеличиваться и уменьшаться в зависимости от примеров. Этот эффект и способствует обучению сети на основе корреляций входных и выходных данных.
Часть 2: задачка посложнее
Вход Выход 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 0Попробуем предсказать выходные данные на основе трёх входных столбцов данных. Ни один из входных столбцов не коррелирует на 100% с выходным. Третий столбец вообще ни с чем не связан, поскольку в нём всю дорогу содержатся единицы. Однако и тут можно увидеть схему – если в одном из двух первых столбцов (но не в обоих сразу) содержится 1, то результат также будет равен 1.
Это нелинейная схема, поскольку прямого соответствия столбцов один к одному не существует. Соответствие строится на комбинации входных данных, столбцов 1 и 2.
Интересно, что распознавание образов является очень похожей задачей. Если у вас есть 100 картинок одинакового размера, на которых изображены велосипеды и курительные трубки, присутствие на них определённых пикселей в определённых местах не коррелирует напрямую с наличием на изображении велосипеда или трубки. Статистически их цвет может казаться случайным. Но некоторые комбинации пикселей не случайны – те, что формируют изображение велосипеда (или трубки).


Стратегия
Чтобы скомбинировать пиксели в нечто, у чего может появиться однозначное соответствие с выходными данными, нужно добавить ещё один слой. Первый слой комбинирует вход, второй назначает соответствие выходу, используя в качестве входных данных выходные данные первого слоя. Обратите внимание на таблицу.Вход (l0) Скрытые веса (l1) Выход (l2) 0 0 1 0.1 0.2 0.5 0.2 0 0 1 1 0.2 0.6 0.7 0.1 1 1 0 1 0.3 0.2 0.3 0.9 1 1 1 1 0.2 0.1 0.3 0.8 0
Случайным образом назначив веса, мы получим скрытые значения для слоя №1. Интересно, что у второго столбца скрытых весов уже есть небольшая корреляция с выходом. Не идеальная, но есть. И это тоже является важной частью процесса тренировки сети. Тренировка будет только усиливать эту корреляцию. Она будет обновлять syn1, чтобы назначить её соответствие выходным данным, и syn0, чтобы лучше получать данные со входа.
Нейросеть в три слоя
import numpy as np def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x)) X = np.array([, , , ]) y = np.array([, , , ]) np.random.seed(1) # случайно инициализируем веса, в среднем - 0 syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 for j in xrange(60000): # проходим вперёд по слоям 0, 1 и 2 l0 = X l1 = nonlin(np.dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # как сильно мы ошиблись относительно нужной величины? l2_error = y - l2 if (j% 10000) == 0: print "Error:" + str(np.mean(np.abs(l2_error))) # в какую сторону нужно двигаться? # если мы были уверены в предсказании, то сильно менять его не надо l2_delta = l2_error*nonlin(l2,deriv=True) # как сильно значения l1 влияют на ошибки в l2? l1_error = l2_delta.dot(syn1.T) # в каком направлении нужно двигаться, чтобы прийти к l1? # если мы были уверены в предсказании, то сильно менять его не надо l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot(l1_delta)Error:0.496410031903 Error:0.00858452565325 Error:0.00578945986251 Error:0.00462917677677 Error:0.00395876528027 Error:0.00351012256786
Переменные и их описания
X - матрица входного набор данных; строки – тренировочные примерыy – матрица выходного набора данных; строки – тренировочные примеры
l0 – первый слой сети, определённый входными данными
l1 – второй слой сети, или скрытый слой
l2 – финальный слой, это наша гипотеза. По мере тренировки должен приближаться к правильному ответу
syn0 – первый слой весов, Synapse 0, объединяет l0 с l1.
syn1 – второй слой весов, Synapse 1, объединяет l1 с l2.
l2_error – промах сети в количественном выражении
l2_delta – ошибка сети, в зависимости от уверенности предсказания. Почти совпадает с ошибкой, за исключением уверенных предсказаний
l1_error – взвешивая l2_delta весами из syn1, мы подсчитываем ошибку в среднем/скрытом слое
l1_delta – ошибки сети из l1, масштабируемые по увеернности предсказаний. Почти совпадает с l1_error, за исключением уверенных предсказаний
Код должен быть достаточно понятным – это просто предыдущая реализация сети, сложенная в два слоя один над другим. Выход первого слоя l1 – это вход второго слоя. Что-то новое есть лишь в следующей строке.
L1_error = l2_delta.dot(syn1.T)
Использует ошибки, взвешенные по уверенности предсказаний из l2, чтобы подсчитать ошибку для l1. Получаем, можно сказать, ошибку, взвешенную по вкладам – мы подсчитываем, какой вклад в ошибки в l2 вносят значения в узлах l1. Этот шаг и называется обратным распространением ошибок. Затем мы обновляем syn0, используя тот же алгоритм, что и в варианте с нейросетью из двух слоёв.
Оригинал: Creating a Neural Network in Python
Автор: John Serrano
Дата публикации: 26 мая 2016 г.
Перевод: А.Панин
Дата перевода: 6 декабря 2016 г.
Нейронные сети являются крайне сложными программами, доступными для понимания лишь академикам и гениям, с которыми по определению не могут работать обычные разработчики, не говоря уже обо мне. Вы ведь так думаете?
Ну, на самом деле все совсем не так. После отличного выступления Луиса Моньера и Грега Ренарда в Колледже Холбертон я понял, что нейронные сети являются достаточно простыми для понимания и реализации любым разработчиком программами. Разумеется, самые сложные сети представляют собой масштабные проекты с элегантной и замысловатой архитектурой, но положенные в их основу концепции также являются более или менее очевидными. Разработка любой нейронной сети с нуля может оказаться достаточно сложной задачей, но, к счастью, существует несколько отличных библиотек, которые могут выполнять всю низкоуровневую работу за вас.
В данном контексте нейрон является довольно простой сущностью. Он принимает несколько входных значений и в том случае, если сумма этих значений превышает заданный предел, активируется. При этом каждое входное значение умножается на его вес. Процесс обучения по сути является процессом установки весов значений для генерации необходимых выходных значений. Сети, которые будут рассматриваться в данной статье, называются сетями "прямого распространения", и это означает, что нейроны в них расположены по уровням, причем их входные данные приходят с предыдущего уровня а выходные - отправляются на следующий уровень.

Существуют нейронные сети и других типов, такие, как рекуррентные нейронные сети, которые организованы отличным образом, но это тема для другой статьи.
Нейрон, работающий по описанному выше принципу, называется перцептроном и основан на оригинальной модели искусственных нейронов, которая на сегодняшний день используется крайне редко. Проблема перцептронов заключается в том, что небольшое изменение входных значений может привести к значительному изменению выходного значения из-за ступенчатой функции активации. При этом незначительное уменьшение входного значения может привести к тому, что внутреннее значение не будет превышать установленный предел и нейрон не будет активироваться, что приведет к еще более значительным изменениям состояния следующих за ним нейронов. К счастью, эта проблема легко решается с помощью более плавной функции активации, которая используется в большинстве современных сетей.


Однако, наша нейронная сеть будет настолько простой, что для ее создания вполне подойдут перцептроны. Мы будем создавать сеть, выполняющую логическую операцию "И". Это означает, что нам понадобятся два входных нейрона и один выходной нейрон, а также несколько нейронов на промежуточном "скрытом" уровне. На иллюстрации ниже показана архитектура данной сети, которая должна быть вполне очевидной.

Моньер и Ренард использовали сценарий convnet.js для создания демонстрационных сетей для своего выступления. Convnet.js может использоваться для создания нейронных сетей непосредственно в вашем веб-браузере, что позволяет вам исследовать и модифицировать их практически на любой платформе. Конечно же, у данной реализации на языке JavaScript присутствуют и значительные недостатки, одним из которых является низкая скорость работы. Ну а в рамках данной статьи мы будем использовать библиотеку FANN (Fast Artifical Neural Networks). При этом на уровне языка программирования Python будет использоваться модуль pyfann, который содержит биндинги для библиотеки FANN. Вам следует установить пакет программного обеспечения с данным модулем прямо сейчас.
Импорт модуля для работы с библиотекой FANN осуществляется следующим образом:
>>> from pyfann import libfann
Теперь мы можем начать работу! Первой операцией, которую нам придется выполнить, является создание пустой нейронной сети.
>>> neural_net = libfann.neural_network()
Созданный объект neural_net на данный момент не содержит нейронов, поэтому давайте попробуем создать их. Для этой цели мы будем использовать функцию libfann.create_standard_array() . Функция create_standard_array() создает нейронную сеть, в которой все нейроны соединены с нейронами из соседних уровней, поэтому ее можно назвать "полностью соединенной" сетью. В качестве параметра функция create_standard_array() принимает массив с числовыми значениями, соответствующими количеству нейронов на каждом из уровней. В нашем случае это массив .
>>> neural_net.create_standard((2, 4, 1))
После этого нам придется установить значение скорости обучения. Данное значение соответствует количеству изменений весов в рамках одной итерации. Мы установим достаточно высокую скорость обучения, равную 0.7 , так как мы будем решать с помощью нашей сети достаточно простую задачу.
>>> neural_net.set_learning_rate(0.7)
Теперь пришло время установить функцию активации, назначение которой обсуждалось выше. Мы будем использовать режим активации SIGMOID_SYMMETRIC_STEPWISE , который соответствует функции ступенчатой аппроксимации гиперболического тангенса. Она является менее точной и более быстрой, чем обычная функция гиперболического тангенса и отлично подходит для нашей задачи.
>>> neural_net.set_activation_function_output(libfann.SIGMOID_SYMMETRIC_STEPWISE)
Наконец, нам нужно запустить алгоритм обучения сети и сохранить данные сети в файле. Функция обучения сети принимает четыре аргумента: имя файла с данными, на основе которых будет осуществляться обучение, максимальное количество попыток запуска алгоритма обучения, количество операций обучения перед выводом данных о состоянии сети, а также частота ошибок.
>>> neural_network.train_on_file("and.data", 10000, 1000, .00001) >>> neural_network.save("and.net")
Файл "and.data" должен содержать следующие данные:
4 2 1 -1 -1 -1 -1 1 -1 1 -1 -1 1 1 1
Первая строка содержит три значения: количество примеров в файле, количество входных значений и количество выходных значений. Ниже расположены строки примеров, причем в строках с двумя значениями приведены входные значения, а в строках с одним значением - выходные.
Вы успешно закончили обучение сети и теперь хотите испытать ее в работе, не так ли? Но сначала нам придется загрузить данные сети из файла, в котором они были сохранены ранее.
>>> neural_net = libfann.neural_net() >>> neural_net.create_from_file("and.net")
После этого мы можем просто активировать ее аналогичным образом:
>>> print neural_net.run()
В результате должно быть выведено значение [-1.0] или аналогичное значение, зависящее от данных сети, сгенерированных в процессе ее обучения.
Поздравляю! Вы только что научили компьютер выполнять простейшие логические операции!
- Перевод
О чём статья
Лично я лучше всего обучаюсь при помощи небольшого работающего кода, с которым могу поиграться. В этом пособии мы научимся алгоритму обратного распространения ошибок на примере небольшой нейронной сети, реализованной на Python.Дайте код!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 for j in xrange(60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0)))) l2 = 1/(1+np.exp(-(np.dot(l1,syn1)))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1)) syn1 += l1.T.dot(l2_delta) syn0 += X.T.dot(l1_delta)Слишком сжато? Давайте разобьём его на более простые части.
Часть 1: Небольшая игрушечная нейросеть
Нейросеть, тренируемая через обратное распространение (backpropagation), пытается использовать входные данные для предсказания выходных.Предположим, нам нужно предсказать, как будет выглядеть колонка «выход» на основе входных данных. Эту задачу можно было бы решить, подсчитав статистическое соответствие между ними. И мы бы увидели, что с выходными данными на 100% коррелирует левый столбец.
Обратное распространение, в самом простом случае, рассчитывает подобную статистику для создания модели. Давайте попробуем.
Нейросеть в два слоя
import numpy as np # Сигмоида def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x)) # набор входных данных X = np.array([ , , , ]) # выходные данные y = np.array([]).T # сделаем случайные числа более определёнными np.random.seed(1) # инициализируем веса случайным образом со средним 0 syn0 = 2*np.random.random((3,1)) - 1 for iter in xrange(10000): # прямое распространение l0 = X l1 = nonlin(np.dot(l0,syn0)) # насколько мы ошиблись? l1_error = y - l1 # перемножим это с наклоном сигмоиды # на основе значений в l1 l1_delta = l1_error * nonlin(l1,True) # !!! # обновим веса syn0 += np.dot(l0.T,l1_delta) # !!! print "Выходные данные после тренировки:" print l1Выходные данные после тренировки: [[ 0.00966449] [ 0.00786506] [ 0.99358898] [ 0.99211957]]
Переменные и их описания.
"*" - поэлементное умножение – два вектора одного размера умножают соответствующие значения, и на выходе получается вектор такого же размера
"-" – поэлементное вычитание векторов
x.dot(y) – если x и y – это вектора, то на выходе получится скалярное произведение. Если это матрицы, то получится перемножение матриц. Если матрица только одна из них – это перемножение вектора и матрицы.
- сравните l1 после первой итерации и после последней
- посмотрите на функцию nonlin.
- посмотрите, как меняется l1_error
- разберите строку 36 – основные секретные ингредиенты собраны тут (отмечена!!!)
- разберите строку 39 – вся сеть готовится именно к этой операции (отмечена!!!)
Разберём код по строчкам
import numpy as npИмпортирует numpy, библиотеку линейной алгебры. Единственная наша зависимость.
Def nonlin(x,deriv=False):
Наша нелинейность. Конкретно эта функция создаёт «сигмоиду». Она ставит в соответствие любое число значению от 0 до 1 и преобразовывает числа в вероятности, а также имеет несколько других полезных для тренировки нейросетей свойств.
If(deriv==True):
Эта функция также умеет выдавать производную сигмоиды (deriv=True). Это одно из её полезных свойств. Если выход функции – это переменная out, тогда производная будет out * (1-out). Эффективно.
X = np.array([ , …
Инициализация массива входных данных в виде numpy-матрицы. Каждая строка – тренировочный пример. Столбцы – это входные узлы. У нас получается 3 входных узла в сети и 4 тренировочных примера.
Y = np.array([]).T
Инициализирует выходные данные. ".T" – функция переноса. После переноса у матрицы y есть 4 строки с одним столбцом. Как и в случае входных данных, каждая строка – это тренировочный пример, и каждый столбец (в нашем случае один) – выходной узел. У сети, получается, 3 входа и 1 выход.
Np.random.seed(1)
Благодаря этому случайное распределение будет каждый раз одним и тем же. Это позволит нам проще отслеживать работу сети после внесения изменений в код.
Syn0 = 2*np.random.random((3,1)) – 1
Матрица весов сети. syn0 означает «synapse zero». Так как у нас всего два слоя, вход и выход, нам нужна одна матрица весов, которая их свяжет. Её размерность (3, 1), поскольку у нас есть 3 входа и 1 выход. Иными словами, l0 имеет размер 3, а l1 – 1. Поскольку мы связываем все узлы в l0 со всеми узлами l1, нам требуется матрица размерности (3, 1).
Заметьте, что она инициализируется случайным образом, и среднее значение равно нулю. За этим стоит достаточно сложная теория. Пока просто примем это как рекомендацию. Также заметим, что наша нейросеть – это и есть эта самая матрица. У нас есть «слои» l0 и l1, но они представляют собой временные значения, основанные на наборе данных. Мы их не храним. Всё обучение хранится в syn0.
For iter in xrange(10000):
Тут начинается основной код тренировки сети. Цикл с кодом повторяется многократно и оптимизирует сеть для набора данных.
Первый слой, l0, это просто данные. В X содержится 4 тренировочных примера. Мы обработаем их все и сразу – это называется групповой тренировкой . Итого мы имеем 4 разных строки l0, но их можно представить себе как один тренировочный пример – на этом этапе это не имеет значения (можно было загрузить их 1000 или 10000 без всяких изменений в коде).
L1 = nonlin(np.dot(l0,syn0))
Это шаг предсказания. Мы позволяем сети попробовать предсказать вывод на основе ввода. Затем мы посмотрим, как это у неё получается, чтобы можно было подправить её в сторону улучшения.
В строке содержится два шага. Первый делает матричное перемножение l0 и syn0. Второй передаёт вывод через сигмоиду. Размерности у них следующие:
(4 x 3) dot (3 x 1) = (4 x 1)
Матричные умножения требуют, чтобы в середине уравнения размерности совпадали. Итоговая матрица имеет количество строк, как у первой, а столбцов – как у второй.
Мы загрузили 4 тренировочных примера, и получили 4 догадки (матрица 4х1). Каждый вывод соответствует догадке сети для данного ввода.
L1_error = y - l1
Поскольку в l1 содержатся догадки, мы можем сравнить их разницу с реальностью, вычитая её l1 из правильного ответа y. l1_error – вектор из положительных и отрицательных чисел, характеризующий «промах» сети.
А вот и секретный ингредиент. Эту строку нужно разбирать по частям.
Первая часть: производная
Nonlin(l1,True)
L1 представляет три этих точки, а код выдаёт наклон линий, показанных ниже. Заметьте, что при больших значениях вроде x=2.0 (зелёная точка) и очень малые, вроде x=-1.0 (фиолетовая) линии имеют небольшой уклон. Самый большой угол у точки х=0 (голубая). Это имеет большое значение. Также отметьте, что все производные лежат в пределах от 0 до 1.
Полное выражение: производная, взвешенная по ошибкам
L1_delta = l1_error * nonlin(l1,True)
Математически существуют более точные способы, но в нашем случае подходит и этот. l1_error – это матрица (4,1). nonlin(l1,True) возвращает матрицу (4,1). Здесь мы поэлементно их перемножаем, и на выходе тоже получаем матрицу (4,1), l1_delta.
Умножая производные на ошибки, мы уменьшаем ошибки предсказаний, сделанных с высокой уверенностью. Если наклон линии был небольшим, то в сети содержится либо очень большое, либо очень малое значение. Если догадка в сети близка к нулю (х=0, у=0,5), то она не особенно уверенная. Мы обновляем эти неуверенные предсказания и оставляем в покое предсказания с высокой уверенностью, умножая их на величины, близкие к нулю.
Syn0 += np.dot(l0.T,l1_delta)
Мы готовы к обновлению сети. Рассмотрим один тренировочный пример. В нём мы будем обновлять веса. Обновим крайний левый вес (9.5)
Weight_update = input_value * l1_delta
Для крайнего левого веса это будет 1.0 * l1_delta. Предположительно, это лишь незначительно увеличит 9.5. Почему? Поскольку предсказание было уже достаточно уверенным, и предсказания были практически правильными. Небольшая ошибка и небольшой наклон линии означает очень небольшое обновление.
Но поскольку мы делаем групповую тренировку, указанный выше шаг мы повторяем для всех четырёх тренировочных примеров. Так что это выглядит очень похоже на изображение вверху. Так что же делает наша строчка? Она подсчитывает обновления весов для каждого веса, для каждого тренировочного примера, суммирует их и обновляет все веса – и всё одной строкой.
Понаблюдав за обновлением сети, вернёмся к нашим тренировочным данным. Когда и вход, и выход равны 1, мы увеличиваем вес между ними. Когда вход 1, а выход – 0, мы уменьшаем вес.
Вход Выход 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
Таким образом, в наших четырёх тренировочных примерах ниже, вес первого входа по отношению к выходу будет постоянно увеличиваться или оставаться постоянным, а два других веса будут увеличиваться и уменьшаться в зависимости от примеров. Этот эффект и способствует обучению сети на основе корреляций входных и выходных данных.
Часть 2: задачка посложнее
Вход Выход 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 0Попробуем предсказать выходные данные на основе трёх входных столбцов данных. Ни один из входных столбцов не коррелирует на 100% с выходным. Третий столбец вообще ни с чем не связан, поскольку в нём всю дорогу содержатся единицы. Однако и тут можно увидеть схему – если в одном из двух первых столбцов (но не в обоих сразу) содержится 1, то результат также будет равен 1.
Это нелинейная схема, поскольку прямого соответствия столбцов один к одному не существует. Соответствие строится на комбинации входных данных, столбцов 1 и 2.
Интересно, что распознавание образов является очень похожей задачей. Если у вас есть 100 картинок одинакового размера, на которых изображены велосипеды и курительные трубки, присутствие на них определённых пикселей в определённых местах не коррелирует напрямую с наличием на изображении велосипеда или трубки. Статистически их цвет может казаться случайным. Но некоторые комбинации пикселей не случайны – те, что формируют изображение велосипеда (или трубки).
Стратегия
Чтобы скомбинировать пиксели в нечто, у чего может появиться однозначное соответствие с выходными данными, нужно добавить ещё один слой. Первый слой комбинирует вход, второй назначает соответствие выходу, используя в качестве входных данных выходные данные первого слоя. Обратите внимание на таблицу.Вход (l0) Скрытые веса (l1) Выход (l2) 0 0 1 0.1 0.2 0.5 0.2 0 0 1 1 0.2 0.6 0.7 0.1 1 1 0 1 0.3 0.2 0.3 0.9 1 1 1 1 0.2 0.1 0.3 0.8 0
Случайным образом назначив веса, мы получим скрытые значения для слоя №1. Интересно, что у второго столбца скрытых весов уже есть небольшая корреляция с выходом. Не идеальная, но есть. И это тоже является важной частью процесса тренировки сети. Тренировка будет только усиливать эту корреляцию. Она будет обновлять syn1, чтобы назначить её соответствие выходным данным, и syn0, чтобы лучше получать данные со входа.
Нейросеть в три слоя
import numpy as np def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x)) X = np.array([, , , ]) y = np.array([, , , ]) np.random.seed(1) # случайно инициализируем веса, в среднем - 0 syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 for j in xrange(60000): # проходим вперёд по слоям 0, 1 и 2 l0 = X l1 = nonlin(np.dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # как сильно мы ошиблись относительно нужной величины? l2_error = y - l2 if (j% 10000) == 0: print "Error:" + str(np.mean(np.abs(l2_error))) # в какую сторону нужно двигаться? # если мы были уверены в предсказании, то сильно менять его не надо l2_delta = l2_error*nonlin(l2,deriv=True) # как сильно значения l1 влияют на ошибки в l2? l1_error = l2_delta.dot(syn1.T) # в каком направлении нужно двигаться, чтобы прийти к l1? # если мы были уверены в предсказании, то сильно менять его не надо l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot(l1_delta)Error:0.496410031903 Error:0.00858452565325 Error:0.00578945986251 Error:0.00462917677677 Error:0.00395876528027 Error:0.00351012256786
Переменные и их описания
X - матрица входного набор данных; строки – тренировочные примерыy – матрица выходного набора данных; строки – тренировочные примеры
l0 – первый слой сети, определённый входными данными
l1 – второй слой сети, или скрытый слой
l2 – финальный слой, это наша гипотеза. По мере тренировки должен приближаться к правильному ответу
syn0 – первый слой весов, Synapse 0, объединяет l0 с l1.
syn1 – второй слой весов, Synapse 1, объединяет l1 с l2.
l2_error – промах сети в количественном выражении
l2_delta – ошибка сети, в зависимости от уверенности предсказания. Почти совпадает с ошибкой, за исключением уверенных предсказаний
l1_error – взвешивая l2_delta весами из syn1, мы подсчитываем ошибку в среднем/скрытом слое
l1_delta – ошибки сети из l1, масштабируемые по увеернности предсказаний. Почти совпадает с l1_error, за исключением уверенных предсказаний
Код должен быть достаточно понятным – это просто предыдущая реализация сети, сложенная в два слоя один над другим. Выход первого слоя l1 – это вход второго слоя. Что-то новое есть лишь в следующей строке.
L1_error = l2_delta.dot(syn1.T)
Использует ошибки, взвешенные по уверенности предсказаний из l2, чтобы подсчитать ошибку для l1. Получаем, можно сказать, ошибку, взвешенную по вкладам – мы подсчитываем, какой вклад в ошибки в l2 вносят значения в узлах l1. Этот шаг и называется обратным распространением ошибок. Затем мы обновляем syn0, используя тот же алгоритм, что и в варианте с нейросетью из двух слоёв.
Мы сейчас переживаем настоящий бум нейронных сетей. Их применяют для распознания, локализации и обработки изображений. Нейронные сети уже сейчас умеют многое что не доступно человеку. Нужно же и самим вклиниваться в это дело! Рассмотрим нейтронную сеть которая будет распознавать числа на входном изображении. Все очень просто: всего один слой и функция активации. Это не позволит нам распознать абсолютно все тестовые изображения, но мы справимся с подавляющим большинством. В качестве данных будем использовать известную в мире распознания чисел подборку данных MNIST.
Для работы с ней в Python есть библиотека python-mnist. Что-бы установить:
Pip install python-mnist
Теперь можем загрузить данные
From mnist import MNIST mndata = MNIST("/path_to_mnist_data_folder/") tr_images, tr_labels = mndata.load_training() test_images, test_labels = mndata.load_testing()
Архивы с данными нужно загрузить самостоятельно, а программе указать путь к каталогу с ними. Теперь переменные tr_images и test_images содержат изображения для тренировки сети и тестирования соотвественно. А переменные tr_labels и test_labels - метки с правильной классификацией (т.е. цифры с изображений). Все изображения имеют размер 28х28. Зададим переменную с размером.
Img_shape = (28, 28)
Преобразуем все данные в массивы numpy и нормализуем их (приведем к размеру от -1 до 1). Это увеличит точность вычислений.
Import numpy as np for i in range(0, len(test_images)): test_images[i] = np.array(test_images[i]) / 255 for i in range(0, len(tr_images)): tr_images[i] = np.array(tr_images[i]) / 255
Отмечу, что хоть и изображения принято представлять в виде двумерного массива мы будем использовать одномерный, это проще для вычислений. Теперь нужно понять "что же такое нейронная сеть"! А это просто уравнение с большим количеством коэффициентов. Мы имеем на входе массив из 28*28=784 элементов и еще по 784 веса для определения каждой цифры. В процессе работы нейронной сети нужно перемножить значения входов на веса. Сложить полученные данные и добавить смещение. Полученный результат подать на функцию активации. В нашем случае это будет Relu. Эта функция равна нулю для всех отрицательных аргументов и аргументу для всех положительных.

Есть еще много функций активации! Но это же самая простая нейронная сеть! Определим эту функцию при помощи numpy
Def relu(x): return np.maximum(x, 0)
Теперь чтобы вычислить изображение на картинке нужно просчитать результат для 10 наборов коэффициентов.
Def nn_calculate(img): resp = list(range(0, 10)) for i in range(0,10): r = w[:, i] * img r = relu(np.sum(r) + b[i]) resp[i] = r return np.argmax(resp)
Для каждого набора мы получим выходной результат. Выход с наибольшим результатом вероятнее всего и есть наше число.

В данном случае 7. Вот и все! Но нет... Ведь нужно эти самые коэффициенты где-то взять. Нужно обучить нашу нейронную сеть. Для этого применяют метод обратного распространения ошибки. Его суть в том чтобы рассчитать выходы сети, сравнить их с правильными, а затем отнять от коэффициентов числа необходимые чтобы результат был правильным. Нужно помнить, что для того чтобы вычислить эти значения нужна производная функции активации. В нашем случае она равна нулю для всех отрицательных чисел и 1 для всех положительных. Определим коэффициенты случайным образом.
W = (2*np.random.rand(10, 784) - 1) / 10 b = (2*np.random.rand(10) - 1) / 10 for n in range(len(tr_images)): img = tr_images[n] cls = tr_labels[n] #forward propagation resp = np.zeros(10, dtype=np.float32) for i in range(0,10): r = w[i] * img r = relu(np.sum(r) + b[i]) resp[i] = r resp_cls = np.argmax(resp) resp = np.zeros(10, dtype=np.float32) resp = 1.0 #back propagation true_resp = np.zeros(10, dtype=np.float32) true_resp = 1.0 error = resp - true_resp delta = error * ((resp >= 0) * np.ones(10)) for i in range(0,10): w[i] -= np.dot(img, delta[i]) b[i] -= delta[i]
В процессе обучения коэффициенты станут слегка похожи на числа:
Проверим точность работы:
Def nn_calculate(img): resp = list(range(0, 10)) for i in range(0,10): r = w[i] * img r = np.maximum(np.sum(r) + b[i], 0) #relu resp[i] = r return np.argmax(resp) total = len(test_images) valid = 0 invalid = for i in range(0, total): img = test_images[i] predicted = nn_calculate(img) true = test_labels[i] if predicted == true: valid = valid + 1 else: invalid.append({"image":img, "predicted":predicted, "true":true}) print("accuracy {}".format(valid/total))
У меня получилось 88%. Не так уж круто, но очень интересно!